


Auth0 uses different datastores for different purposes. We have tons of datasets used to serve the wide variety of use cases and features we offer to our customers. In an age where data breaches are unfortunately getting more common, a critical side of choosing and using datastores is to consider reliability, durability, and safety. Our platform processes thousands of requests per second (billions of logins per month) for customers all around the world — and we're growing very fast!
The Site Reliability team is a new initiative aimed at improving reliability and uptime in a data-driven way to support our customers' needs. Our team works closely with other teams to define and apply best practices through coding, writing, workshops, training, and leading different initiatives related to reliability, performance, and observability.
In this post, we will discuss the tools we use, why we use them and show more details about our internal setup. Some of these tools have been with us since the beginning — like MongoDB — while others are the result of extensive testing, research, and feature development — like PostgreSQL. Read on!
Do you like to get your hands dirty by debugging and fixing issues in production? We are currently hiring engineers to join the Site Reliability Engineering team!
MongoDB
MongoDB is our central datastore; it's our "source of truth" for most of the data that matter to our customers. We store settings, connections, rules, users, and much more.
Our MongoDB clusters serve many thousands of requests per second, but we don't store that much data: our biggest MongoDB database has 30 GB.
Given that our data sizes are tiny, we're still very comfortable with just a few big machines (tons of RAM and CPU cores, and high-speed disks) and we don't need fancy things like sharding — we can still do much with vertical scaling, and we still don't need horizontal scaling.
As explained by David Beaumont from IBM on the article How to explain vertical and horizontal scaling in the cloud, vertical scaling can essentially resize our server with no change to our code while horizontal scaling affords the ability to scale wider to deal with traffic.
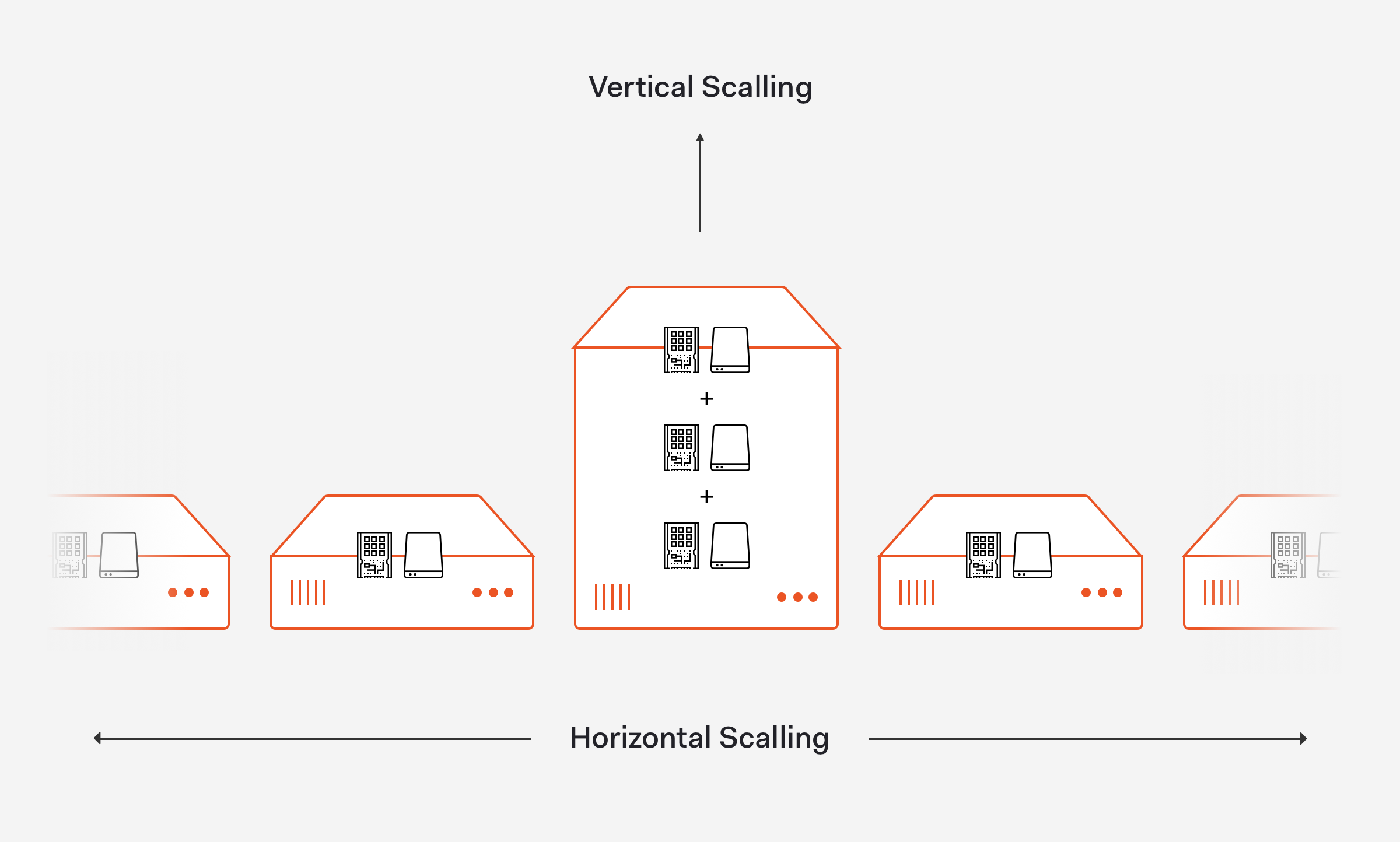
Each MongoDB cluster has six nodes:
- 1 Primary on the main region
- 1 Replica on the main region
- 1 Arbiter on the main region
- 2 Replicas on the failover region, hidden
- 1 Arbiter on the failover region, stopped
(The "main" and "failover" regions are explained in more details on our Running In Multiple Cloud Providers And Regions post).
Except for the arbiter on the failover region, all nodes are always connected to the replica set. We have a primary and replica that account for all queries under normal operations, and the nodes for failover regions just for disaster recovery.
We use MongoDB Enterprise for all our cloud deployments: this helps us because of the additional metrics and also because of the excellent support we get from MongoDB.
The most challenging side of using MongoDB has been performance testing new queries: since we have multiple environments and regions with a wildly different datasets and usage patterns, sometimes MongoDB might simply decide to not use an index for some reason. We rely on $hint for specific queries and focus on performance testing for the critical collections and code paths.
"The most challenging part of using MongoDB has been performance testing new queries since we have multiple environments and regions with a wildly different data sets and usage patterns."
Tweet This

Since the conception of Auth0, MongoDB has been an essential piece of our infrastructure, and it should continue to be a massive part of our stack for a long time; it allowed us to iterate fast, grow to more than 1.5 billion authentication operations per month — and more.
Elasticsearch
We have a long story with Elasticsearch, and not always a happy one. We use Elasticsearch to store three types of data for search:
- User metadata.
- Audit logs: logs that our tenants can access via dashboard and API.
- Application logs: logs from our micro-services and "off-the-shelf" solutions like NGINX and MongoDB (running Kibana).
Those are kept in completely separate clusters with different permissions, backup strategies, and Elasticsearch configuration. We have 3-5 clusters per environment.
We have almost 80 Elasticsearch nodes in the US environment only. If we sum up all environments and regions, we probably have short of 200 big nodes running ES. Yikes! 💸
Our application logs clusters are by far the best ones. ES was pretty much made to deal with those kinds of logs, and besides occasional resizes we don't have many problems with them from an infrastructure perspective. We store 2.3TB of data per day on them.
We have had our issues with user metadata and audit logs on Elasticsearch though. Part of the reason is that we outgrew the tool, at least in the use case we have: we need to store hundreds of thousands of different fields for search, completely separated by tenant, and we need to scale for tenants with 1-10 users but also tenants with 6-8 million users. Due to the performance and stability issues, we have decided to migrate two of those three use cases to PostgreSQL (more on that later).
Elasticsearch shines for general logging; if you use common patterns (daily indexes, metadata templates, hot and cold nodes), it can be a very powerful and stable tool.
Even for cases in which we found it not to be entirely adequate (user metadata and audit log search), it was certainly a great tool while we didn't reach "critical mass". Elasticsearch helped us scale fast and gave us stability for years before we outgrew it.
"Due to performance and stability issues with Elasticsearch, we decided to migrate two of its three use cases to PostgreSQL. It was certainly a great tool while we didn't reach critical mass."
Tweet This
PostgreSQL
We have three main databases stored in PostgreSQL running on AWS RDS:
- Breached passwords
- User metadata (search v3)
- Tenant audit logs (under development)
Breached password detection protects and notifies your users when their credentials are leaked by a data breach of a third party. You can optionally prevent access until the user has reset their password. This feature uses a big PostgreSQL database as a backend: we have a subscription with a company that provides us with breached data, which we then import for querying.
Given the scalability issues we faced with Elasticsearch, we have completely rewritten the user metadata search feature into what we call User Search v3, and we're gradually migrating tenants to that new solution: it uses PostgreSQL instead of Elasticsearch for storage and search.
The performance differences between Elasticsearch and PostgreSQL are massive: instead of 300 thousand metadata writes per minute per cluster, we can have up to 10 million writes per minute (on bulk operations), all with roughly the same infrastructure costs but with far less operational overhead (thank you AWS RDS 💖).
Given the outstanding results of search v3 regarding performance and stability, we decided also to migrate our tenant logs feature. This is under active development and testing, but we expect great results from it.
In the future, we plan to keep using PostgreSQL more and more wherever it makes sense. As we gain more operational knowledge and build tooling around it, it will definitely become a big contender with MongoDB as the preferred storage choice for new microservices: it's safe, fast, well documented, and very easy to operate.
"The performance differences between Elasticsearch and PostgreSQL are massive: we can have up to 10 million writes per minute, all with roughly the same infrastructure costs but with far less operational overhead."
Tweet This
Redis
I don't have much to say on this one actually. Redis is just so... awesome. It's fast, it's stable, and we barely have to think about it, doing tens of thousands of requests per second on surprisingly small instances.
We use Redis for caching, not long-term storage; our "distribution of choice" for the cloud is AWS ElastiCache.
"Redis is... awesome! We use it for caching with a cloud distribution through AWS ElastiCache."
Tweet This
Recap
Auth0 is growing, and it's growing fast. Two years ago we were happy with Elasticsearch; now, we outgrew it for some of our use cases.
As we increase in size and scale, we are focusing more and more on performance and reliability testing on the datastores we use and some that we might use in the future. We are starting to use tools like AWS DynamoDB for some secondary operations, and might test others (RocksDB?) as we get new exciting use cases and features for our customers!
About Auth0
Auth0 by Okta takes a modern approach to customer identity and enables organizations to provide secure access to any application, for any user. Auth0 is a highly customizable platform that is as simple as development teams want, and as flexible as they need. Safeguarding billions of login transactions each month, Auth0 delivers convenience, privacy, and security so customers can focus on innovation. For more information, visit https://auth0.com.


